第一部分 编程技巧
1. 字符串
substr()
vs2008 可以使用substr, 具体使用方法substr(起始地址, 截取长度)
string a = "sdfsdfs";
string sub_a = a.substr(2,2);//输出fs
string 赋值
= 将 a 赋值给 b
b = a;
string 赋值用 assign 将 a 赋值给 b
b.assign(a);
string 输入
string a;
cin >> a;
string 输出
不格式化,用cout比较方便
string a = "12345";
cout << a;
当 string 遇到 printf 时
使用 string 配合 printf("%s") 使用时,要注意使用 a.c_str() 将 string 转化成 char *
解决在vs2008较老IDE上无法使用stoi()的替代方案
string str = "12345";
int num = atoi(str.c_str());
数字<==>字符
可以使用 1 = ‘1’ - ‘0’(‘1’ = 1 + ‘0’)实现
英文同理
数字<==>字符串(string)
char str[10];
string s;
int a = 1234321;
sprintf(str, "%d", a);//除了第一个输出参数 后面两个参数和printf一样
s = str;//赋值即可将 char * 转化为 string
2. 变量初始化
使用全局变量,在定义时,系统会自动初始化
int a[5];//会自动初始化 全0
bool a[5];//会自动初始化 全false
3. map
map 判断键值是否存在
map<key,value>举例,find()方法返回值是一个迭代器,成功返回迭代器指向要查找的元素,失败返回的迭代器指向end。count()方法返回值是一个整数,1表示有这个元素,0表示没有这个元素。
使用 map 可以方便查询一个元素是否在线性表中
a.count(b);//b是否在a中,等于0表示不在,等于1表示在
4. 格式输出问题
若结果为double等浮点数时,需要输出整数部分,尽量提前强制转换,避免后续出现比较问题
5. 比较问题
遇到编号时 使用string来定义避免不必要的麻烦
对于编号的判等
如089 和 89是不一样的,要使用 strcmp 来判断
double float 比较
不能直接使用 ==
6. C/C++语言常用函数
algorithm头
fill
//语法描述fill(begin, end, val) val为替换的值
//一维数组
fill(a, a+4, val);
//二维数组
fill(a[0], a[0]+4*4, val);
//vector
fill(v.begin(), v.end(), val);
sort
//语法描述sort(begin, end, cmp) cmp参数可以没有,如果没有默认非降序排序
bool cmp(int a, int b)
{
//排序规则
if(a == b)
return a < b;
}
//数组
int a[4] = {1,2,3,4};
sort(a, a+4, cmp);
//vector
vector<int> v;
sort(v.begin(), v.end(), cmp);
copy
int a[] = {1,2,3,4}, b[4];
copy(a, a+4, b);//将a拷贝给b
string/cstring头
sprintf
char str_2[10];
int a = 1234321;
sprintf(str_2, "%d", a);//将数字a转化为char字符数组(字符串)输出到str_2中
atoi
//字符串(char *)转数字
7. 宏定义 常量定义
#define N 123 //宏定义 后面没有;
const int N = 123;//常量定义
queue头
priority_queue优先队列
priority_queue<int, vector<int>, greater<int> > q;//从小到大的优先级队列,可将greater改为less,即为从大到小
第二部分 数学问题
1. 求最大公约数与最小公倍数
最大公约数(辗转相除法)
int gcd(int a, int b)
{
if(b == 0)
return a;
else
return gcd(b, a%b);
}
最小公倍数
int lcm(int a, int b)
{
return (a/gcd(a, b))*b;//防止(a*b)/gcd(a, b)计算溢出
}
2. 素数判断
bool isPrime(int n)
{
if(n < 2)
return false;
for(int i = 2; i * i < n; i++)
{
if(n % i == 0)
return false;
}
return true;
}
第三部分 常见数据结构
1. 链表
静态链表题基本套路
//首先定义链表节点结构体
struct Node{
int address;//地址
int val;
int nextAd;//下一个地址
};
//定义大数组,保存输入的节点信息 用于输入之后处理
Node list[100001];
//输入示例
for(int i = 1; i <= n; i++)//从1开始遍历
{
scanf("%d%d%d", &a, &b, &c);
list[a].address = a;
list[a].val = b;
list[a].nextAd = c;
}
//定义链表向量 用于存储整理后的链表(由乱变为顺序结构)
vector<Node> v, res;
//处理过程示例 ad表示初始地址
for(;ad != -1; ad = list[ad].nextAd)
v.push_back(list[ad]);
//剩下的就是根据题意的最后处理,并将处理结果保存在res中
2. 图
连通分量
强连通分量
邻接表与邻接矩阵
邻接矩阵比较方便,但在数据量很大的时候,邻接表比较节省空间
图的遍历
DFS
一般使用DFS可以解决图的遍历、查并集等问题
邻接矩阵版
int g[1001][1001], n;//邻接矩阵
bool vis[1001];//访问记录
void dfs(int u)
{
vis[u] = true;
for(int i = 0; i < n; i++)
{
if(vis[i] == false && g[u][i] != INF)
dfs(i);
}
}
void DFSTrave()
{
for(int u = 0; u < n; u++)//对每个结点
{
if(vis[u] == false)
dfs(u);//访问u和u所在的连通块
}
}
邻接表版
vector<int> g[1001];//邻接矩阵
int n;//顶点数
bool vis[1001];//访问记录
void dfs(int u)
{
vis[u] = true;
for(int i = 0; i < g[u].size(); i++)
{
int v = g[u][i];
if(vis[v] == false)
dfs(v);
}
}
void DFSTrave()
{
for(int u = 0; u < n; u++)//对每个结点
{
if(vis[u] == false)
dfs(u);//访问u和u所在的连通块
}
}
BFS
int g[1001][1001], n;
bool inq[1001] = {false};//是否入队
void BFS(int u)
{
queue<int> q;
q.push(u);
inq[u] = true;
while(!q.empty())
{
int u = q.front();//取出队首元素
q.pop();//队首元素出队
for(int v = 0; v < n; v++)
{
//找到未入队并且是u点的后驱结点
if(inq[v] == false && g[u][v] != INF)
q.push(v);
inq[v] = true;
}
}
}
void BFSTrave()
{
for(int u = 0; u < n; u++)
{
if(inq[u] == false)
{
BFS(u);
}
}
}
Dijkstra
const int INF = 99999999;//常量定义
const int MAXV = 1001;
int g[MAXV][MAXV], nv;//nv顶点个数 g也需要初始化 当然这里没有写出来
bool vis[MAXV] = {false};
int dis[MAXV];
void dijkstra(int s)//s是起点
{
fill(dis, dis+MAXV, INF);
dis[s] = 0;
for(int i = 0; i < nv; i++)//对每个点 每次访问一个点
{
int u = -1, min = INF;
for(int j = 1; j <= nv; j++)
{
if(vis[j] == false && dis[j] < min)
{
min = dis[j];
u = j;
}
}
if(u == -1)
{
break;
}
vis[u] = true;
for(int v = 1; v <= nv; v++)
{
if(vis[v] == false && g[u][v] != INF && dis[u] + g[u][v] < dis[v])
dis[v] = dis[u] + g[u][v];//优化
}
}
}
3. 树
完全二叉树
除了最下面一层之外,其余层的结点个数都达到了当前层能达到的最大结点数,且最下面一层只从左到右连续存在若干结点,而这些连续结点右边不存在结点。
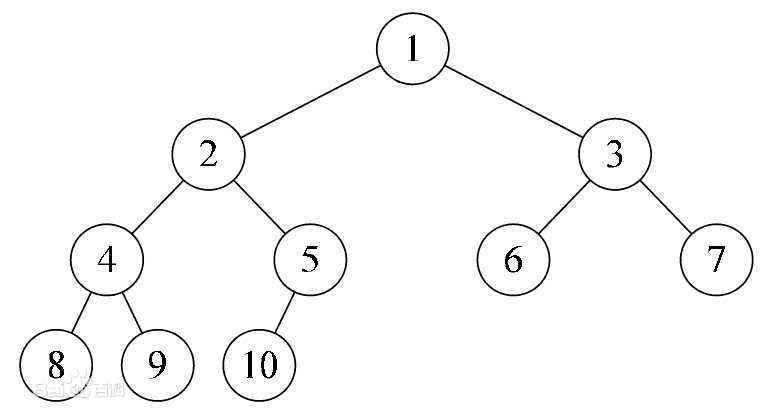
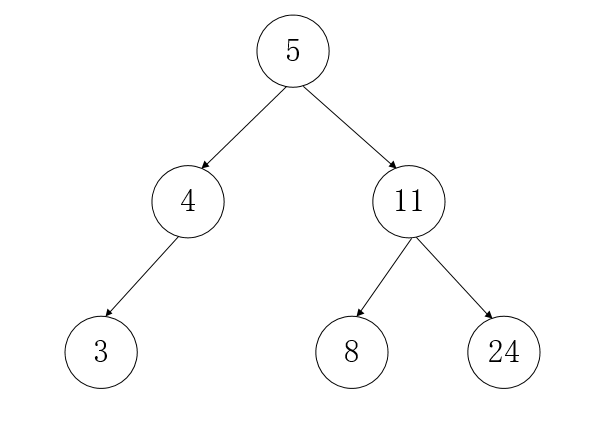
二叉搜索树/二叉查找树/二叉排序树(BST, binary search tree)
A binary search tree (BST) is recursively defined as a binary tree which has the following properties:
- The left subtree of a node contains only nodes with keys less than the node’s key.
- The right subtree of a node contains only nodes with keys greater than or equal to the node’s key.
- Both the left and right subtrees must also be binary search trees.
根节点的值大于其左子树中任意一个节点的值,小于其右子树中任意一节点的值,这一规则适用于二叉搜索树中的每一个节点。
特点
BST的中序遍历 就是结点值的排序
二叉树的建立
- 根据前序和中序或者后序和中序可以确定唯一的二叉树
- 根据给定完全二叉树的层次遍历序列可以计算出每个点的下标,即确定唯一的二叉树
- 根据给定的二叉搜索树(BST)的前序或后序序列可以确定唯一的二叉树。因为前序或后序可以确定根节点,通过根节点,可以计算出根节点的左子树和右子树包含哪些成员,以此类推。
struct node{//树结点
int val;
node *left;
node *right;
}
//在需要建树的题目中 可以使用如下代码开辟结点空间
node *t = new node;
二叉树遍历
//树结点结构为
struct node{
int val, left, right;//left/right没有结点用-1表示
};
void travel(int root)//dfs
{
if(list[root].left != -1)
travel(list[root].left);
//访问根节点
if(list[root].right != -1)
travel(list[root].right);
}
//也可这样 建议这样子
void travel(int root)//dfs
{
if(root == -1)
return;
travel(list[root].left);
//访问根节点
travel(list[root].right);
}
树的前中后序遍历即是树的DFS
前序
void preorder(node *root)
{
if(root == NULL)
return;
printf("%d\n", root->data);//访问根节点
preorder(root->lchild);
preorder(root->rchild);
}
中序
void inorder(node *root)
{
if(root == NULL)
return;
preorder(root->lchild);
printf("%d\n", root->data);//访问根节点
preorder(root->rchild);
}
后序
void postorder(node *root)
{
if(root == NULL)
return;
preorder(root->lchild);
preorder(root->rchild);
printf("%d\n", root->data);//访问根节点
}
BFS 层次 (队列)
void LayerOrder(node *root)
queue<node*> q;
q.push(root);
while(!q.empty())
{
node *now = q.front();//取出队首元素
q.pop();
printf(" %d", now->val);
if(now->left != NULL)
q.push(now->left);
if(now->right != NULL)
q.push(now->right);
}
}