DDL操作
DDL的全称为Data Definition Language,翻译为数据库定义语言
创建数据库
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_option] ...
create_option: [DEFAULT] {
CHARACTER SET [=] charset_name
| COLLATE [=] collation_name
}
删除数据库
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name
创建表
例:
CREATE TABLE `bilibili_video_info` (
`id` int(10) NOT NULL AUTO_INCREMENT COMMENT '视频编号',
`pic` varchar(255) NOT NULL COMMENT '视频预览图地址',
`pubdate` varchar(20) NOT NULL COMMENT '视频发布时间',
`desc` text NOT NULL COMMENT '视频简介',
`title` varchar(255) NOT NULL COMMENT '视频标题',
`owner_name` varchar(50) NOT NULL COMMENT '视频作者',
`view` int(10) NOT NULL COMMENT '视频播放数',
`rank` int(10) DEFAULT NULL COMMENT '视频排名',
`category` varchar(255) NOT NULL COMMENT '视频类别',
`get_time` varchar(50) DEFAULT NULL COMMENT '视频挖掘时间',
`url` varchar(255) DEFAULT NULL COMMENT '视频播放地址',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE KEY `url` (`url`) USING BTREE COMMENT '唯一索引'
) ENGINE=InnoDB AUTO_INCREMENT=1447 DEFAULT CHARSET=utf8mb4 ROW_FORMAT=DYNAMIC
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,...)
[table_options]
[partition_options]
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
[(create_definition,...)]
[table_options]
[partition_options]
[IGNORE | REPLACE]
[AS] query_expression
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
{ LIKE old_tbl_name | (LIKE old_tbl_name) }
create_definition: {
col_name column_definition
| {INDEX | KEY} [index_name] [index_type] (key_part,...)
[index_option] ...
| {FULLTEXT | SPATIAL} [INDEX | KEY] [index_name] (key_part,...)
[index_option] ...
| [CONSTRAINT [symbol]] PRIMARY KEY
[index_type] (key_part,...)
[index_option] ...
| [CONSTRAINT [symbol]] UNIQUE [INDEX | KEY]
[index_name] [index_type] (key_part,...)
[index_option] ...
| [CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (col_name,...)
reference_definition
| CHECK (expr)
}
column_definition: {
data_type [NOT NULL | NULL] [DEFAULT default_value]
[AUTO_INCREMENT] [UNIQUE [KEY]] [[PRIMARY] KEY]
[COMMENT 'string']
[COLLATE collation_name]
[COLUMN_FORMAT {FIXED | DYNAMIC | DEFAULT}]
[STORAGE {DISK | MEMORY}]
[reference_definition]
| data_type
[COLLATE collation_name]
[GENERATED ALWAYS] AS (expr)
[VIRTUAL | STORED] [NOT NULL | NULL]
[UNIQUE [KEY]] [[PRIMARY] KEY]
[COMMENT 'string']
[reference_definition]
}
data_type:
(see Chapter 11, Data Types)
key_part:
col_name [(length)] [ASC | DESC]
index_type:
USING {BTREE | HASH}
index_option: {
KEY_BLOCK_SIZE [=] value
| index_type
| WITH PARSER parser_name
| COMMENT 'string'
}
reference_definition:
REFERENCES tbl_name (key_part,...)
[MATCH FULL | MATCH PARTIAL | MATCH SIMPLE]
[ON DELETE reference_option]
[ON UPDATE reference_option]
reference_option:
RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT
table_options:
table_option [[,] table_option] ...
table_option: {
AUTO_INCREMENT [=] value
| AVG_ROW_LENGTH [=] value
| [DEFAULT] CHARACTER SET [=] charset_name
| CHECKSUM [=] {0 | 1}
| [DEFAULT] COLLATE [=] collation_name
| COMMENT [=] 'string'
| COMPRESSION [=] {'ZLIB' | 'LZ4' | 'NONE'}
| CONNECTION [=] 'connect_string'
| {DATA | INDEX} DIRECTORY [=] 'absolute path to directory'
| DELAY_KEY_WRITE [=] {0 | 1}
| ENCRYPTION [=] {'Y' | 'N'}
| ENGINE [=] engine_name
| INSERT_METHOD [=] { NO | FIRST | LAST }
| KEY_BLOCK_SIZE [=] value
| MAX_ROWS [=] value
| MIN_ROWS [=] value
| PACK_KEYS [=] {0 | 1 | DEFAULT}
| PASSWORD [=] 'string'
| ROW_FORMAT [=] {DEFAULT | DYNAMIC | FIXED | COMPRESSED | REDUNDANT | COMPACT}
| STATS_AUTO_RECALC [=] {DEFAULT | 0 | 1}
| STATS_PERSISTENT [=] {DEFAULT | 0 | 1}
| STATS_SAMPLE_PAGES [=] value
| TABLESPACE tablespace_name [STORAGE {DISK | MEMORY}]
| UNION [=] (tbl_name[,tbl_name]...)
}
partition_options:
PARTITION BY
{ [LINEAR] HASH(expr)
| [LINEAR] KEY [ALGORITHM={1 | 2}] (column_list)
| RANGE{(expr) | COLUMNS(column_list)}
| LIST{(expr) | COLUMNS(column_list)} }
[PARTITIONS num]
[SUBPARTITION BY
{ [LINEAR] HASH(expr)
| [LINEAR] KEY [ALGORITHM={1 | 2}] (column_list) }
[SUBPARTITIONS num]
]
[(partition_definition [, partition_definition] ...)]
partition_definition:
PARTITION partition_name
[VALUES
{LESS THAN {(expr | value_list) | MAXVALUE}
|
IN (value_list)}]
[[STORAGE] ENGINE [=] engine_name]
[COMMENT [=] 'string' ]
[DATA DIRECTORY [=] 'data_dir']
[INDEX DIRECTORY [=] 'index_dir']
[MAX_ROWS [=] max_number_of_rows]
[MIN_ROWS [=] min_number_of_rows]
[TABLESPACE [=] tablespace_name]
[(subpartition_definition [, subpartition_definition] ...)]
subpartition_definition:
SUBPARTITION logical_name
[[STORAGE] ENGINE [=] engine_name]
[COMMENT [=] 'string' ]
[DATA DIRECTORY [=] 'data_dir']
[INDEX DIRECTORY [=] 'index_dir']
[MAX_ROWS [=] max_number_of_rows]
[MIN_ROWS [=] min_number_of_rows]
[TABLESPACE [=] tablespace_name]
query_expression:
SELECT ... (Some valid select or union statement)
删除表
DROP [TEMPORARY] TABLE [IF EXISTS]
tbl_name [, tbl_name] ...
[RESTRICT | CASCADE]
修改表
ALTER TABLE tbl_name
[alter_option [, alter_option] ...]
[partition_options]
alter_option: {
table_options
| ADD [COLUMN] col_name column_definition
[FIRST | AFTER col_name]
| ADD [COLUMN] (col_name column_definition,...)
| ADD {INDEX | KEY} [index_name]
[index_type] (key_part,...) [index_option] ...
| ADD {FULLTEXT | SPATIAL} [INDEX | KEY] [index_name]
(key_part,...) [index_option] ...
| ADD [CONSTRAINT [symbol]] PRIMARY KEY
[index_type] (key_part,...)
[index_option] ...
| ADD [CONSTRAINT [symbol]] UNIQUE [INDEX | KEY]
[index_name] [index_type] (key_part,...)
[index_option] ...
| ADD [CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (col_name,...)
reference_definition
| ADD CHECK (expr)
| ALGORITHM [=] {DEFAULT | INPLACE | COPY}
| ALTER [COLUMN] col_name {
SET DEFAULT {literal | (expr)}
| DROP DEFAULT
}
| CHANGE [COLUMN] old_col_name new_col_name column_definition
[FIRST | AFTER col_name]
| [DEFAULT] CHARACTER SET [=] charset_name [COLLATE [=] collation_name]
| CONVERT TO CHARACTER SET charset_name [COLLATE collation_name]
| {DISABLE | ENABLE} KEYS
| {DISCARD | IMPORT} TABLESPACE
| DROP [COLUMN] col_name
| DROP {INDEX | KEY} index_name
| DROP PRIMARY KEY
| DROP FOREIGN KEY fk_symbol
| FORCE
| LOCK [=] {DEFAULT | NONE | SHARED | EXCLUSIVE}
| MODIFY [COLUMN] col_name column_definition
[FIRST | AFTER col_name]
| ORDER BY col_name [, col_name] ...
| RENAME {INDEX | KEY} old_index_name TO new_index_name
| RENAME [TO | AS] new_tbl_name
| {WITHOUT | WITH} VALIDATION
}
DML操作
DML的全称为Data Manipulation Language,翻译为数据库操纵语言
插入
insert into table_name(col1, col2, ...) values(val1, val2, ...)
更新
update table_name set col = val where ...
删除
delete from table_name where ...
查询
select col1, col2 from table_name where ...
排序
关键字:order by
默认排序规则为升序(
ASC),若需要降序排序需要指定关键字DESC,而且DESC关键字只应用到位于其前面的列名,因此要想在多个列上进行降序排序,必须对每一列指定DESC关键字。
select col1, col2 from table_name order by table_name.num
数据过滤
关键字:where
在同时使用
order by和where语句时,注意要让order by语句位于where语句之后,否则会产生错误。
# 同样类似的where也适用于delete和update
select col2, col2 from table_name where ...
where语句有如下常用运算符:
| 符号 | 含义 |
|---|---|
= |
等于 |
> |
大于 |
< |
小于 |
>= |
大于等于 |
<= |
小于等于 |
<>,!= |
不等于 |
between ... and ... |
一个值是否在范围中 |
not between ... and ... |
一个值是否不在范围中 |
in |
一个值是否在一组值内 |
not in |
一个值是否不在一组值内 |
like |
简单的模式匹配 |
not like |
简单模式匹配的否定 |
is |
针对布尔值的测试 |
is not |
针对布尔值的测试 |
is null |
空值测试 |
is not null |
非空值测试 |
另外,使用and和or关键字可以组合任意多的逻辑表达式已完成复杂的过滤。需要注意的是and的优先级高于or。
通配符
like操作符
在where子句中使用通配符,必须使用like操作符
百分号(%)
%表示任何字符出现任意次数
%能匹配0个、1个或多个字符
# 匹配hello起头的值
select col from table_name where col like 'hello%';
# 匹配任何位置上包含hello文本的值
select col from table_name where col like '%hello%';
# 匹配中间部分可以是任意值的值
select col from table_name where col like 'hel%lo';
# 注意!下面语句不会匹配col为null的值
select col from table_name where col like '%'
下划线(_)
下划线_的用法和百分号%用途一样,但只能匹配单个字符,而不是多个字符
聚合函数
MySQL支持有很多聚合函数,但比较常见主要有以下5种:
| 函数 | 说明 |
|---|---|
AVG() |
返回某列的平均值 |
COUNT() |
返回某列的行数 |
MAX() |
返回某列的最大值 |
MIN() |
返回某列的最小值 |
SUM() |
返回某列值之和 |
AVG()
# 计算col列的平均值(若带有where条件,则只计算满足条件的col列的平均值)
select avg(col) from table_name [where id = ...]
COUNT()
# 统计所有的行数包括null
count(*)
# 统计所有的行数包括null
count(1)
# 统计当前列的行数不包括null
count(col)
注意,有很多地方说count(1)性能要由于count(*),但实际上二者在高版本MySQL(5.5及以上)毫无区别。所以这里推荐使用count(*)
参考文档https://zhuanlan.zhihu.com/p/28397595
MAX()
select max(view) from table_name
MIN()
select min(view) from table_name
SUM()
select sum(view) from table_name
联表
MySQL支持三种类型的连接:
- 内连接(
inner join) - 左连接(
left join) - 右连接(
right join)
注意:在MySQL中
join,cross join以及inner join是等效的,可以互相替换。
以下是连接的具体用法、含义以及实验结果:
创建实验表并插入数据
创建表
CREATE TABLE t1 (
id INT PRIMARY KEY,
user_name VARCHAR(50) NOT NULL
);
CREATE TABLE t2 (
id INT PRIMARY KEY,
user_name VARCHAR(50) NOT NULL,
grade INT NOT NULL
);
插入数据
insert into t1(id, user_name)
values(1, "小明"),
(2, "小红"),
(3, "小黄");
insert into t2(id, user_name, grade)
values(1, "小红", 90),
(2, "小黄", 100),
(3, "小绿", 95);
效果如下:
inner join
select t1.user_name, t2.grade from t1 inner join t2 on t1.user_name = t2.user_name;
sql执行结果如下:
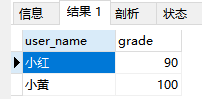
很明显可以看出,inner join只对左右表完全等值的记录才会作连接(可以简单理解为两个表的交集)。
left join
select t1.user_name, t2.grade from t1 left join t2 on t1.user_name = t2.user_name;
sql执行结果如下:
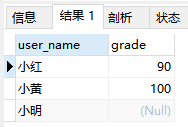
可以看到,left join将左侧表作为主表,根据连接谓词条件,与右表中的记录进行比较,满足连接谓词条件的记录与左表进行合并,不满足的用NULL来表示。
right join
select col1, col2 from table_name1 right join table_name2 on table_name1.id = table_name2.id
sql执行结果如下:
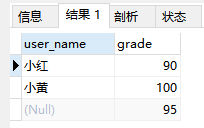
right join的结果与left join刚好相反,right join将右侧表作为主表,根据连接谓词条件,与左表中的记录进行比较,满足连接谓词条件的记录与右表进行合并,不满足的用NULL来表示。
组合
视图
存储过程
事务
常用show命令
| 命令 | 功能 |
|---|---|
| show create table 表名 | 显示表创建语句 |
| show engine innodb status | 查看死锁日志 |